1. Unicode 字符编码模型
Unicode 及其并行标准 ISO/IEC 10646 通用字符集(Universal Character Set, UCS)共同构成了现代统一的字符编码。它们不是将字符直接映射到八位字节,而是分别定义了哪些字符可用、字符对应的自然数(代码点)、这些数字如何编码成一系列固定尺寸的自然数(代码单元),以及这些代码单元如何被编码成八位字节流。之所以这么分解,是为了建立一个可以使用多种方式进行编码的通用字符集。
Universal Character Set, UCS Universal Coded Character Set, UCS, Unicode
本文将重点介绍 Unicode 字符编码模型,旨在帮助大家理解现代字符编码的整个过程。
字符编码模型
Unicode 字符编码模型,可以概况为四个层级:
抽象字符库:即要编码的字符,比如某些字母表和符号集
编码字符集:从抽象字符库到一组非负整数(即代码点)的映射
字符编码形式:从代码点到特定宽度(比如32-bit整数)的代码单元序列的映射
字符编码方案:从代码单元序列到字节序列的映射
ACR, Abstract Character Repertoire CCS, Coded Character Set CEF, Character Encoding Form CES, Character Encoding Scheme
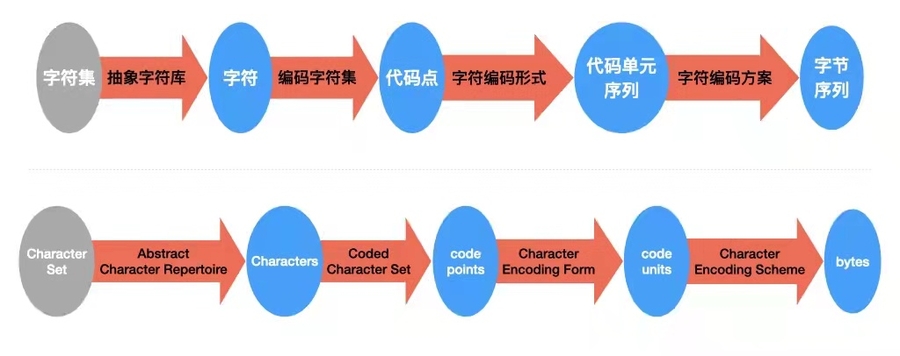
图一. Unicode 字符编码模型(中英版)
此外,还有两个非常有用的概念:
字符映射:是贯穿这四个层级的映射,从字符到字节序列。
传输编码语法:是编码数据的可逆转换,通常是将一种字节流转换为另一种字节流。
CM, Character Map TES, Transfer Encoding Syntax
抽象字符库
字符库就是从字符集里取出的要进行编码的字符集合(一般是无序的),“抽象”一词意味着这些字符是按某种约定定义的。在很多情况下,字符库都是由熟悉的字母表(如26个字母/元素周期表/声母表韵母表/日语音节)或者符号集(如乐谱)组成的。
字符集(CS, Character Set)是用于表示文本信息的元素集合。它是一组超过100万个字符的抽象集合,包括拉丁文/中文/日文/韩文/西里尔文/希伯来文和亚拉姆文等。
字符库有两种类型:固定的和开放的。在大多数字符编码中,库都是固定的(一旦确定就永远不会改变)且通常很小。向给定字符库添加新字符通常是创建一个新库(新库会有自己的目录号)构成一个新对象。
eg1.固定字符库
JIS X 0208 日语音节和表意文字
Latin-1 西欧字母和符号
POSIX 可移植字符库
IBM 主机日语库
eg2.开放字符库
Windows 西欧库
Unicode/10646 库
兼容性字符
由于历史原因,抽象字符库可能包括许多看起来不适当的字符,比如连字字形/上下文形式字形/宽度不同的字形/字符序列/装饰字形(如带圆圈的数字)。所以,字符和代码点之间不一定存在一对一的关系。
eg1.一个字符可能会对应多个代码点
![]()
![]()
![]()
![]()
![]()
阿拉伯语中的上下文字形 (字形可能需要根据周围的字形而 改变其形状/位置/宽度)
![]()
![]()
![]()
![]()
梵文音节
![]()
![]()
![]()
G-ring
eg2.一个代码点对应多个字符
![]()
![]()
![]()
连字字形
![]()
![]()
![]()
![]()
字符序列
编码字符集
编码字符集是从抽象字符库到非负整数的映射,整数的范围可以不连续。非负整数即代码点(code point),分配到代码点的字符就是一个编码字符(an encoded character)。
编码字符集是 ISO 和字符编码委员会生成的基本对象。它们将字符库和代码点相关联,这样就可以用数字明确地指代特定字符了。
编码字符集有时也称为:
Coded Character Set 编码字符集
Character Encoding 字符编码
Coded Character Repertoire 编码字符库
Character Set Definition 字符集定义
eg.编码字符集
Unicode 标准, 版本 4.0 ISO/IEC 10646:2003
ISO/IEC 8859-1:ASCII 加 Latin-1
Code Page 037:和 8859-1 一样的字符库,但分配的整数不同
JIS X 0208:会分配称为kuten点的整数对
"Code Page 037" 中的 Code Page 是 IBM CDRA 架构中的概念,用来指代编码字符集。切记不要把它和常用来指代编码方案的 code page 相混淆。
代码空间
代码点是对“编码字符集”而言的,是编码字符集或者代码空间的值。代码空间就是代码点的整数范围,它通常和字符编码形式密切相关,因为字符到代码点的映射是在考虑特定编码形式(代码点→字节)的情况下完成的。
代码空间也可以有复杂的结构,这取决于整数范围是否连续,或者是否不允许使用特定范围的值。而大多数的“复杂”情况都源于字符编码形式的考虑,比如字符编码形式会限制字节里的控制位不能有值,这就导致了代码空间是多个不连续的整数范围。
eg.代码空间(16进制表示)
0..7F
0..FF
0..FFFF
0..10FFFF
0..7FFFFFFF
0..FFFFFFFF
字符编码形式
字符编码形式是把代码点映射到代码单元序列。代码单元是一个占据特定二进制宽度的整数(比如 8-bit byte),代码单元大小是特定编码的“二进制宽度”的位度量(比如 8 bits)。
代码单元
eg.代码单元
US-ASCII 中的代码单元大小是由 7 bits 组成的
UTF-8/EBCDIC/GB18030 中的代码单元大小是由 8 bits 组成的
UTF-16 中的代码单元大小是由 16 bits 组成的
UTF-32 中的代码单元大小是由 32 bits 组成的
bits 可以表示的整数:
1bit, 2^1=2, 1~1
2bits, 2^2=4, 11~3
3bits, 2^3=8, 111~7
4bits, 2^4=16, 1111~15~F
所以,不同代码单元能表示的数据范围(16进制表示)是:
8-bit, 00~FF
16-bit, 0000~FFFF
32-bit, 00000000~FFFFFFFF
代码单元个数
字符编码形式定义了编码的一个基本方面:每个字符需要多少个代码单元(这对于国际化软件很重要)。以前,这相当于定义每个字符需要多少字节(bytes),但随着 Unicode 和 10646 为 UCS-2, UTF-16, UCS-4 和 UTF-32 引入更宽的代码单元,这就被概括成了两条信息:代码单元大小、每个字符需要的代码单元个数。UCS-2 编码形式是固定宽度的,它和 ISO/IEC 10646 相关,只能表示BMP(基本多语言平面)里的字符。相比之下,UTF-16 可以使用一个或两个代码单元,并且能覆盖 Unicode 的整个代码空间。
UTF-8 可以很好地描述“每个字符需要的代码单元个数”。在 UTF-8 中,用于表示字符的基本代码单元是 8 bits wide(即一个字节),不同字节数就可表示不同范围的字符。
00..7F
1 byte
1 code unit
80..7FF
2 bytes
2 code units
800..D7FF E000..FFFF
3 bytes
3 code units
10000..10FFFF
4 bytes
4 code units
bit, 位, 存储的最小单元 byte = 8 bits, 字节, 信息存储的单元(现存的) code unit = N bytes, N取决于编码形式
固定/可变宽度
编码形式定义了代码单元和每个字符需要的代码单元个数(即代码单元序列的长度)。若序列的长度相同,则字符编码形式称为固定宽度;若序列的长度不同,则称为可变宽度。编码形式有多种类型,其中一些是 Unicode/10646 独有的。
eg1.固定宽度的编码形式
7-bit
7-bit
比如 ISO 646
8-bit G0/G1
8-bit
限制使用C0和C1空间
8-bit
8-bit
对C1空间的使用没有限制
8-bit EBCDIC
8-bit
使用EBCDIC约定而不是ASCII约定
16-bit (UCS-2)
16-bit
在0..FFFF的代码空间内
32-bit (UCS-4)
32-bit
在0..7FFFFFFF的代码空间内
32-bit (UTF-32)
32-bit
在0..10FFFF的代码空间内
16-bit DBCS 进程代码
16-bit
比如亚洲CCS的UNIX宽字符实现
32-bit DBCS 进程代码
32-bit
比如亚洲CCS的UNIX宽字符实现
DBCS主机
两个8-bit
遵循IBM主机约定
eg2.可变宽度的编码形式
UTF-8
在Unicode中是 1~4个 8-bit代码单元 在10646中是 1~6个 8-bit代码单元
Unicode/10646 独有的
UTF-16
1~2个 16-bit代码单元
Unicode/10646 独有的
编码字符集→字符编码形式
在许多情况下,给定的编码字符集只有一种字符编码形式。所以,有时就不显式提编码字符集了,而是直接说字符编码形式,大约就暗含了字符→代码点→代码单元序列。
eg.应用于特定编码字符集的编码形式
JIS X 0208
通常是将kuten符号转换为16-bit “JIS code”编码形式
CP 037
8-bit EBCDIC 编码形式
CP 500
8-bit EBCDIC 编码形式
Windows CP 1252
8-bit 编码形式
US ASCII
7-bit 编码形式
ISO 8859-1
具有 8-bit G0/G1 编码形式(欧洲各国的语言)
ISO 646
7-bit 编码形式(ASCII)
ISO/IEC 10646:2003
根据声明的实现级别,可能有 UCS-2, UCS-4, UTF-16 或 UTF-8
ISO/IEC 10646:2009
UTF-8, UTF-16 或 UTF-32
Unicode 1.1
UCS-2(默认)或 UTF-8 编码形式
Unicode 3.0
UTF-16(默认)或 UTF-8 编码形式
Unicode 4.0 Unicode 5.0
UTF-16, UTF-8 或 UTF-32 编码形式
字符编码方案
字符编码方案是一个可逆变换,它把代码单元序列映射到字节序列。可能是以下三种方式之一:
简单字符编码方案:会把每个代码单元映射到唯一的字节序列,比如 UTF-8, UTF-16BE, UTF-32BE
复合字符编码方案:会使用两个或多个简单字符编码方案,以及一个在它们之间相互转换的机制。这就意味着,可能会有不同的字节序列对应到相同的代码单元。虽然这些字节序列不是唯一的,但它们都可以明确地恢复原始的代码单元序列。
压缩字符编码方案:会把代码单元序列映射到字节序列,同时最小化字节序列的长度。一些压缩字符编码方案是给每个代码单元序列生成唯一的字节序列,这样就可以比较两个压缩字节序列是否相等,也可以通过二进制来对压缩字节进行排序。其它的压缩字符编码方案仅仅是可逆的。
比如 Unicode 标准的七种字符编码方案,分别是:
5种简单字符编码方案
CESUTF-8
UTF-16BE, UTF-16LE
UTF-32BE, UTF-32LE
2种复合字符编码方案
可选的字节顺序标记+简单CES组成UTF-16
UTF-32
Unicode 1.1 有三种字符编码方案:UTF-8 和 UCS-2BE, UCS-2LE(尽管后两个当时并不以这种方式命名)。还有非 Unicode 字符编码方案,此处就不列出来了,感兴趣的小伙伴可以查看底部的“主要参考”。
跨平台
字符编码方案和跨平台持久数据有关(数据的代码单元比字节更宽),其中可能需要字节交换才能把数据放入用于特定平台的字节里。特别是:
大多数固定宽度的面向字节编码形式都有一个到编码方案的简单映射:每 7-bit 或 8-bit 映射到一个相同值的字节
大多数混合宽度的面向字节编码形式也只是将编码字符序列化成字节
UTF-8 遵循这种模式,因为它已经是一种面向字节的编码形式
UTF-16 必须为字节序列指定字节顺序,因为它的代码单元大小是 16 bits(是两个字节)。字节顺序是 UTF-16BE 和 UTF-16LE 之间的唯一区别,前者的两个字节是以大端顺序序列化,而后者是以小端顺序序列化。
字节顺序
在把多字节机器整数(即多字节的代码单元)映射到存储位置的处理上,不同处理器的做法有所不同。LE(Little Endian,小端)是将最低字节放在低地址,即从最低字节开始。而 BE(Big Endian,大端)是从最高有效字节开始。
这种差异在处理内存中的代码单元时无关紧要,但当使用特定的字符编码方案将代码单元序列化为字节序列时,字节顺序就变得很重要了。在读取数据流时,有两种类型的字节顺序:和处理器读数据的字节顺序相同或者相反。前者不需要什么特殊操作,后者需要在处理数据前对字节进行反转。
对于数据流的外部指定,有三种类型的字节顺序:大端(BE)、小端(LE)和默认/内部标记。在数据流的头部,字节顺序标记(byte order mark)的存在可用于明确地表示代码单元的字节顺序。
编码形式 vs 编码方案
不要混淆字符编码形式和字符编码方案:
映射对象不同。字符编码形式是将代码点→代码单元序列,字符编码方案是将代码单元序列→字节序列。
单位不同,当多于一个单位时要考虑的问题点也不同。字符编码形式的单位“代码单元”,当需要多个代码单元时需要考虑代码单元的“个数”。而字符编码方案的单位是“字节”,对于代码单元比一字节宽的,需要考虑字节的“顺序”。
此外,相同的字符编码方案在其它方面也可能不同,比如允许用户定义的字符数(如 IBM CDRA 架构)
一些 Unicode 编码方案和 Unicode 编码形式的名称一样,比如 UTF-8, UTF-16 和 UTF-32。当不加限定地使用时,这些术语的含义是不明确的。这种歧义对于 UTF-8 来说通常是无害的,因为 UTF-8 编码方案是从为 UTF-8 编码形式而定义的字节序列中派生出来的。但是,对于 UTF-16 和 UTF-32 来说二义性是有问题的。
作为编码形式,UTF-16 和 UTF-32 指的是代码单元,即是通过 16-bit 或 32-bit 的数据类型从内存中访问的,但是并没有关联字节方向。作为编码方案,UTF-16 和 UTF-32 指的是序列化字节,例如流数据或文件里的序列化字节,它们可能具有某种字节方向。
字符编码形式:code units,个数即可
字符编码方案:bytes,且有字节方向
所以尽量使用完整术语,诸如 UTF-16 编码形式(UTF-16 CEF)、UTF-16 编码方案(UTF-16 CES)。
字符映射
字符映射(CM, Character Map)就是把抽象字符库里的字符映射到字节序列。所以,一个简单的字符映射就隐含了编码字符集、编码字符形式和编码字符方案,从字符→代码点→代码单元序列→字节序列。一个复合字符映射包含一个复合字符编码方案和一个以上的编码字符形式和编码字符集,此时的抽象字符库就是所涉及的编码字符集所覆盖的字符库的集合。
Unicode 技术报告 # 22: Character Mapping Markup Language (CharMapML) 定义了字符映射的XML规范,还包含了对字符集之间映射问题的详细讨论。
字符映射是从 IAB 架构中获取 IANA charset 标识符的实体。从 IANA charset 的角度来看,重要的是通过 charset 将编码字符序列明确映射到字节序列上。在所有情况下都必须指定 charset,就像在 Internet 协议中一样,其中文本内容被视为有序的字节序列,且文本内容必须可以从该字节序列中重新构造。
IAB, Internet Architecture Board, 互联网架构委员会 IANA, Internet Assigned Numbers Authority, 互联网号码分配机构
在 IBM CDRA 架构中,字符映射是获取编码字符集标识符(CCSID)值的实体。字符映射也称为 charset, character set, code page(广义上)或 CHARMAP.
CDRA, Character Data Representation Architecture CCSID, Coded Character Set Identifier
在许多情况下,字符映射的名字和字符编码方案的相同,例如 UTF-16BE。
总结
本文详细介绍了 Unicode 字符编码的四层模型,如下图:
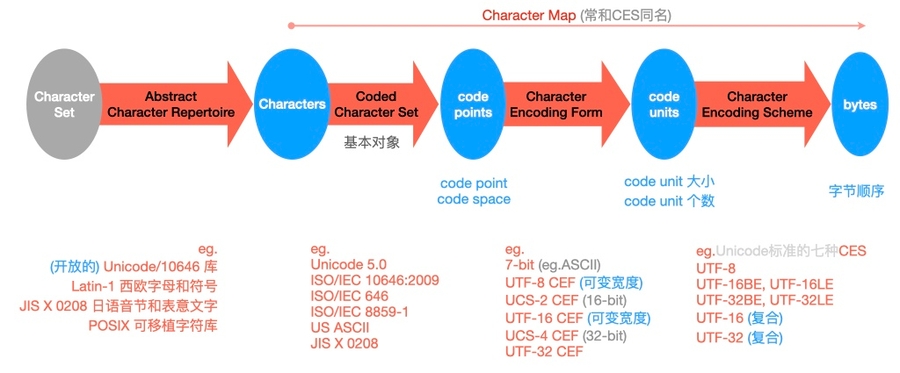
抽象字符库
类型:固定字符库+开放字符库
说明:由于历史原因,字符和代码点不一定是一对一的关系
编码字符集
代码点:编码字符集或代码空间的值
代码空间:代码点的整数范围(通常和字符编码形式相关)
字符编码形式
代码单元个数代码单元+代码单元大小:可以小于等于大于一字节
代码单元个数:即代码单元序列长度,即一个字符需要的代码单元数
类型:固定宽度+可变宽度
字符编码方案
字节顺序简单CES:将代码单元唯一映射到字节序列
复合CES:用2个及以上的简单CES
压缩CES:最小化字节序列的长度
主要参考
Last updated